

目录
快速导航-

综述评论 | 量子计算技术在金融领域的应用探索
综述评论 | 量子计算技术在金融领域的应用探索
-

综述评论 | 基于深度学习的图像拼接算法研究综述
综述评论 | 基于深度学习的图像拼接算法研究综述
-
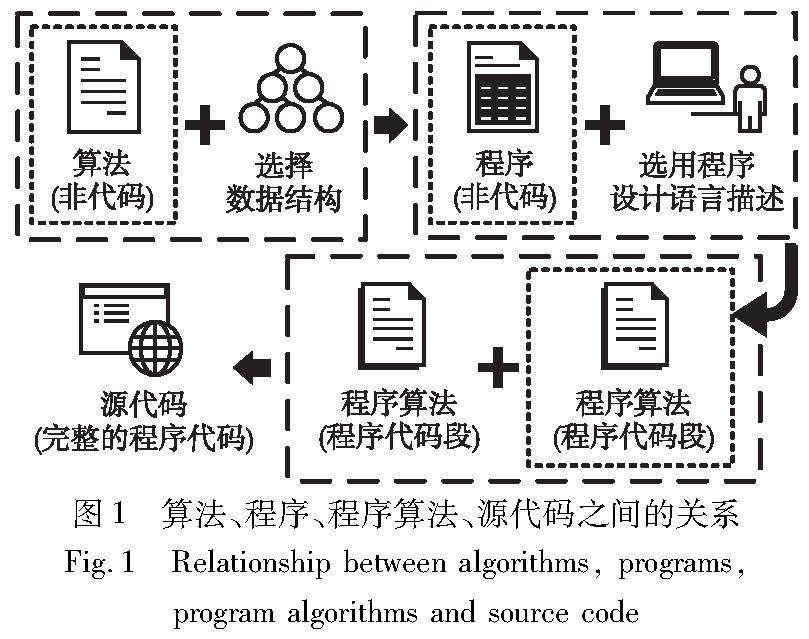
综述评论 | 程序算法识别研究综述
综述评论 | 程序算法识别研究综述
-
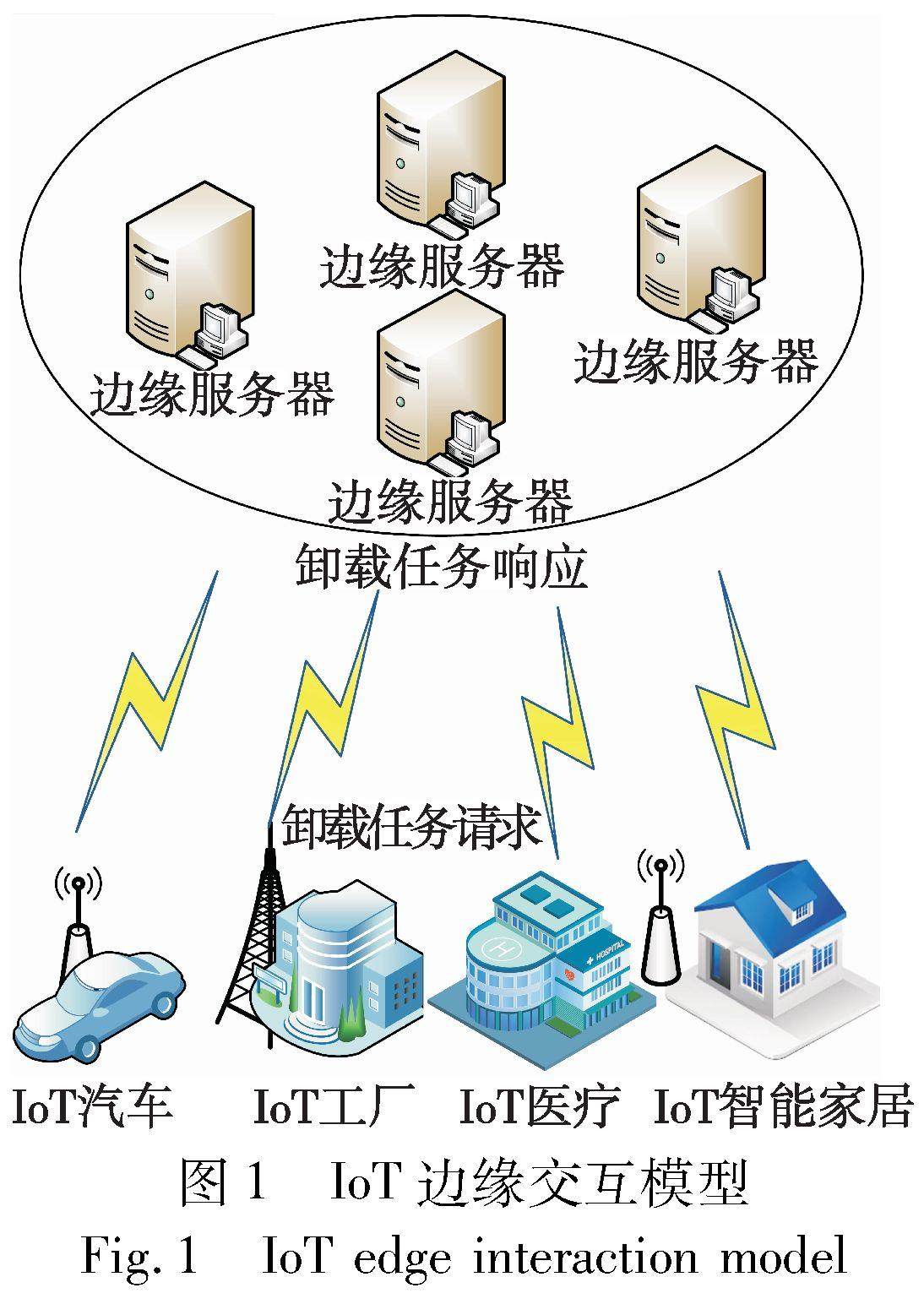
区块链技术 | 面向数据保护的区块链物联网边缘卸载策略
区块链技术 | 面向数据保护的区块链物联网边缘卸载策略
-
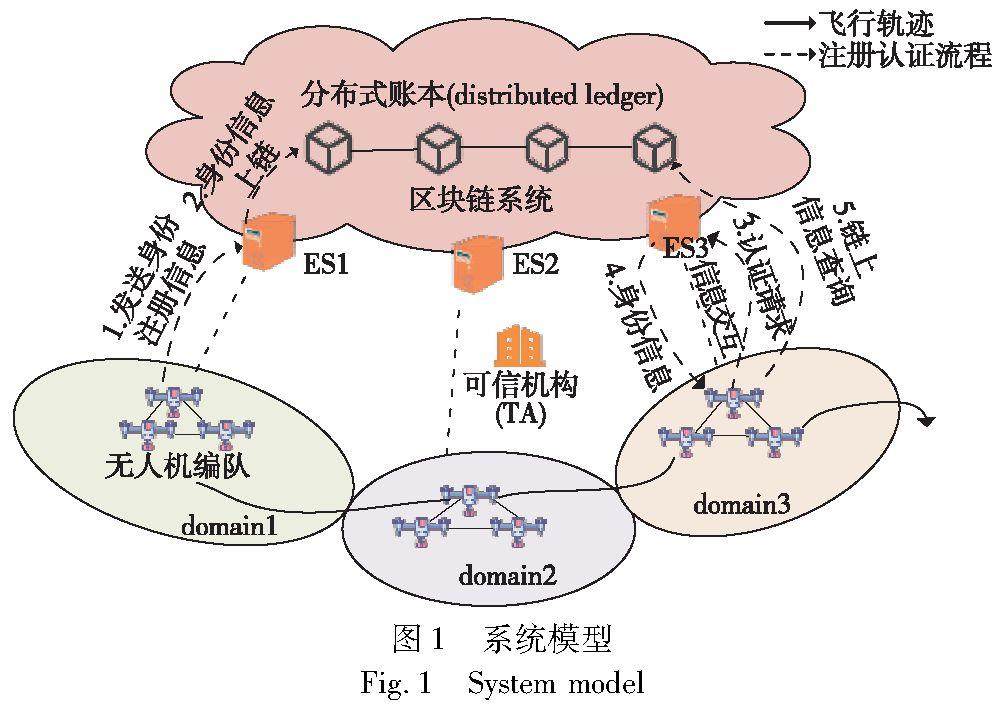
区块链技术 | 基于区块链的无人机网络跨域身份认证研究
区块链技术 | 基于区块链的无人机网络跨域身份认证研究
-
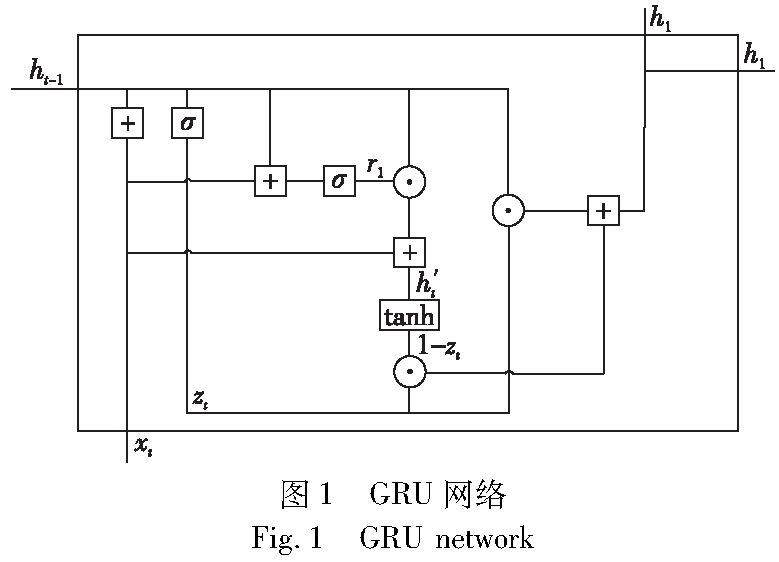
强化学习专题 | 基于GA-TD3算法的交叉路口决策模型
强化学习专题 | 基于GA-TD3算法的交叉路口决策模型
-
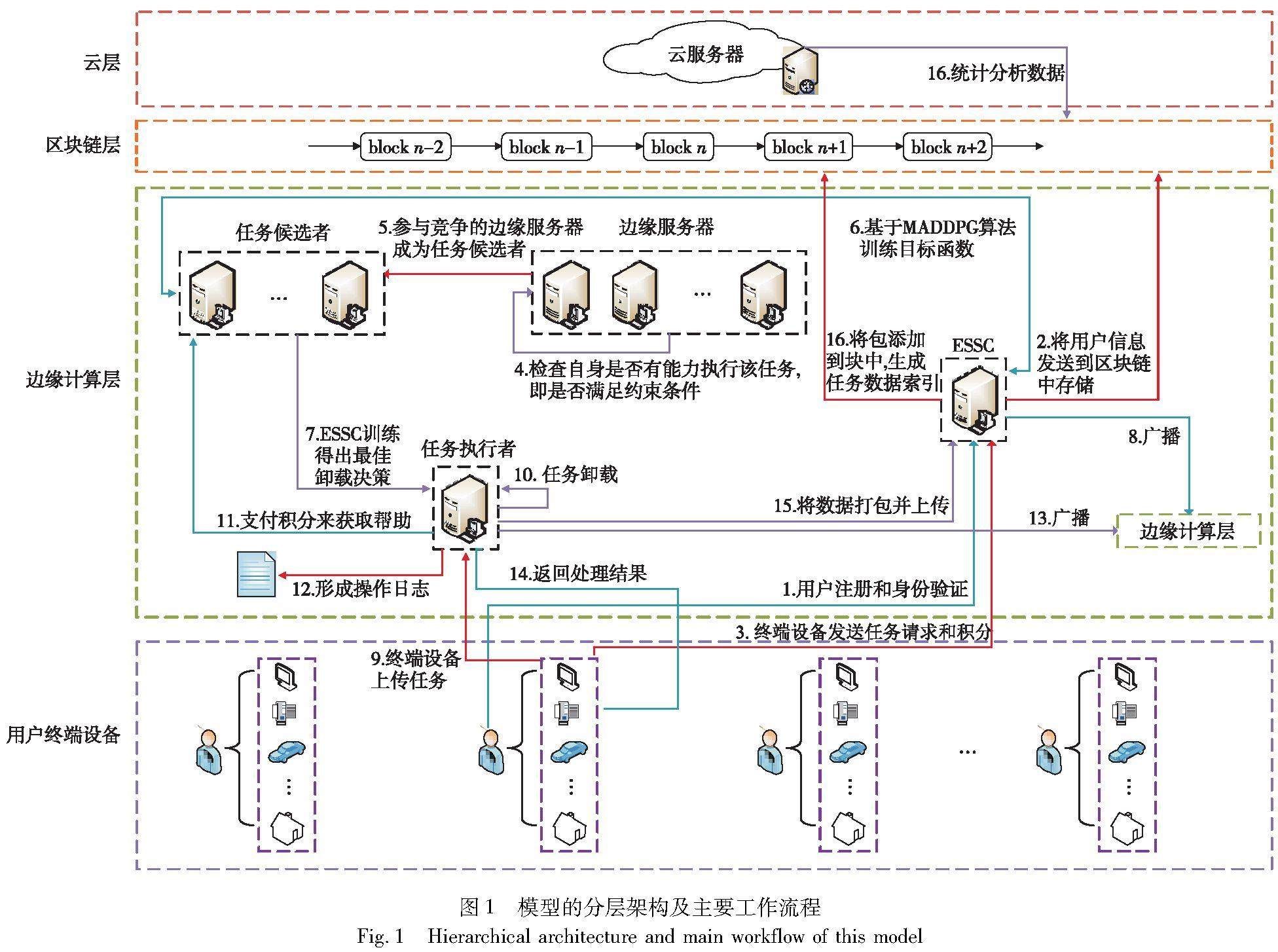
强化学习专题 | 基于多智能体深度强化学习的车联网可信任务卸载策略
强化学习专题 | 基于多智能体深度强化学习的车联网可信任务卸载策略
-

强化学习专题 | 基于强化学习的离散层级萤火虫算法检测蛋白质复合物
强化学习专题 | 基于强化学习的离散层级萤火虫算法检测蛋白质复合物
-
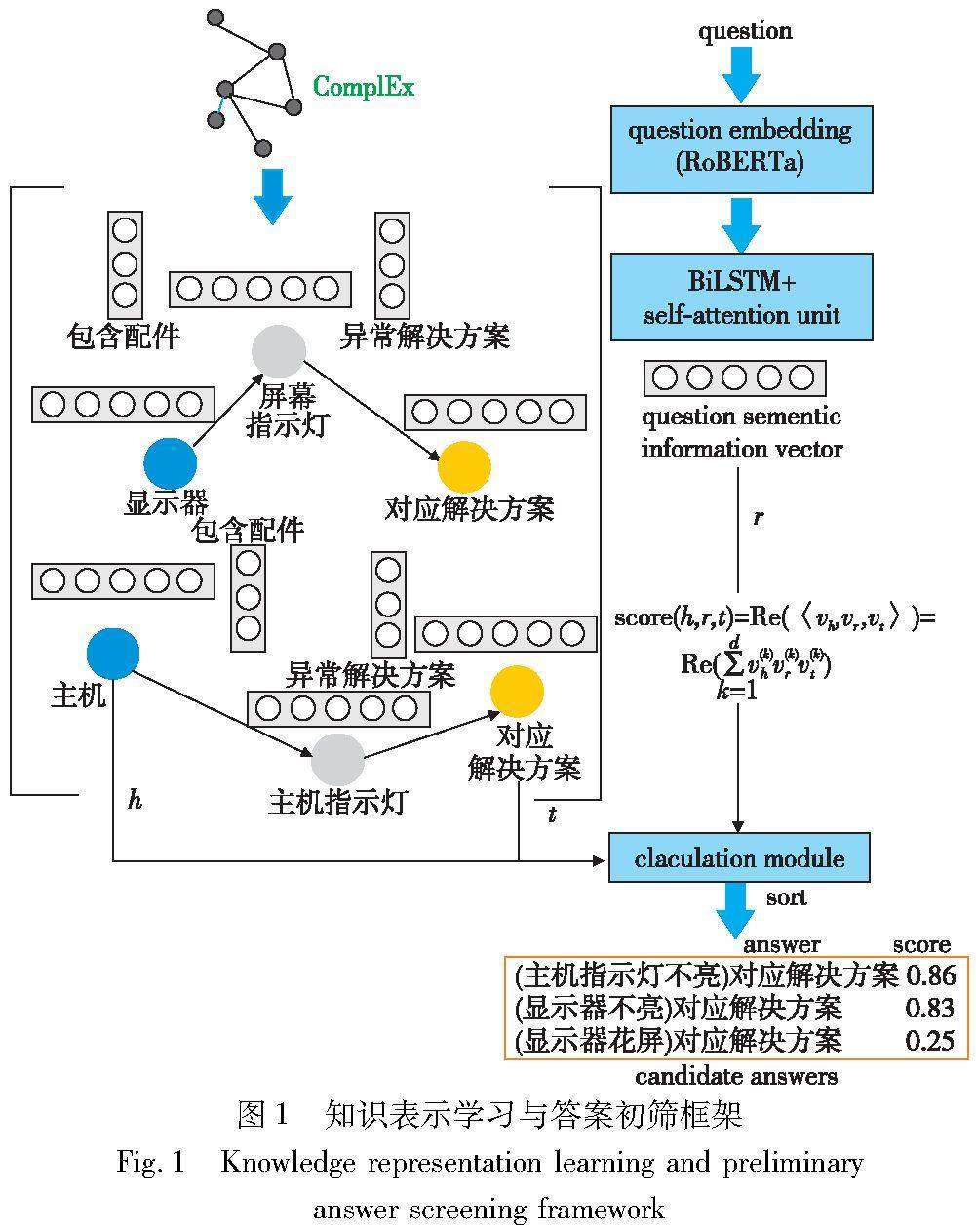
算法研究探讨 | 基于知识表示学习的KBQA答案推理重排序算法
算法研究探讨 | 基于知识表示学习的KBQA答案推理重排序算法
-

算法研究探讨 | 结合社交网络图的多模态虚假信息检测模型
算法研究探讨 | 结合社交网络图的多模态虚假信息检测模型
-
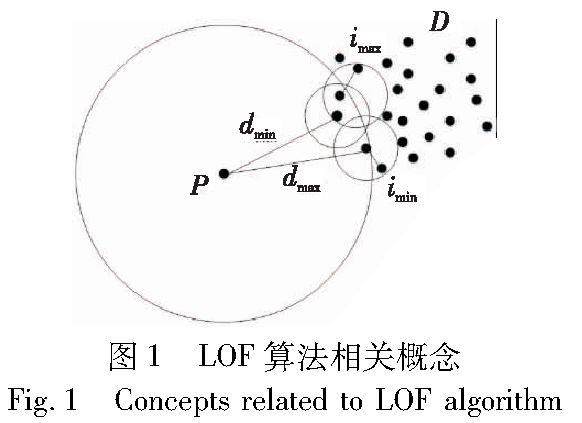
算法研究探讨 | 基于离群点检测和自适应参数的三支DBSCAN算法
算法研究探讨 | 基于离群点检测和自适应参数的三支DBSCAN算法
-
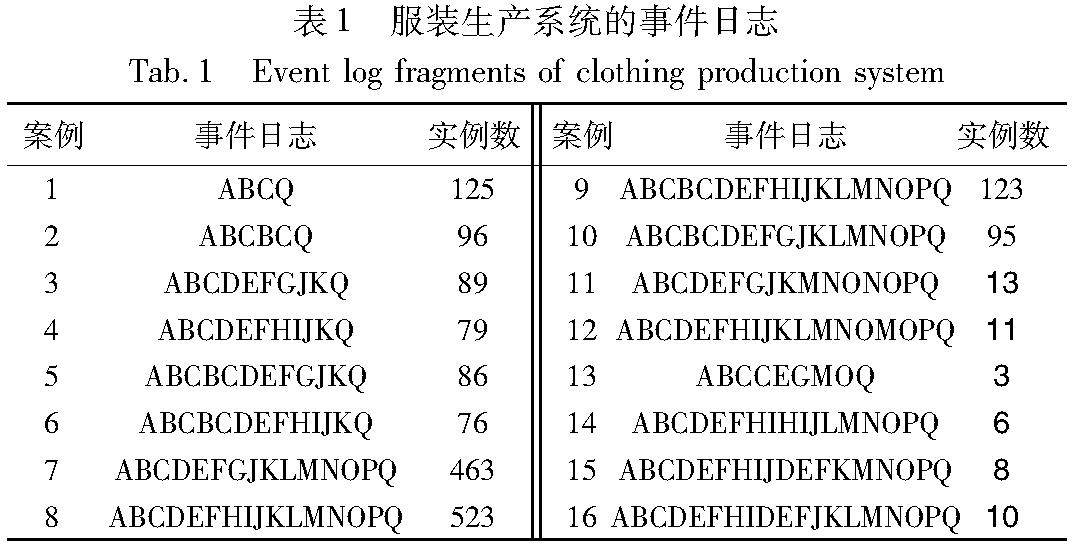
算法研究探讨 | 基于活动恢复集的有效低频行为分析方法
算法研究探讨 | 基于活动恢复集的有效低频行为分析方法
-
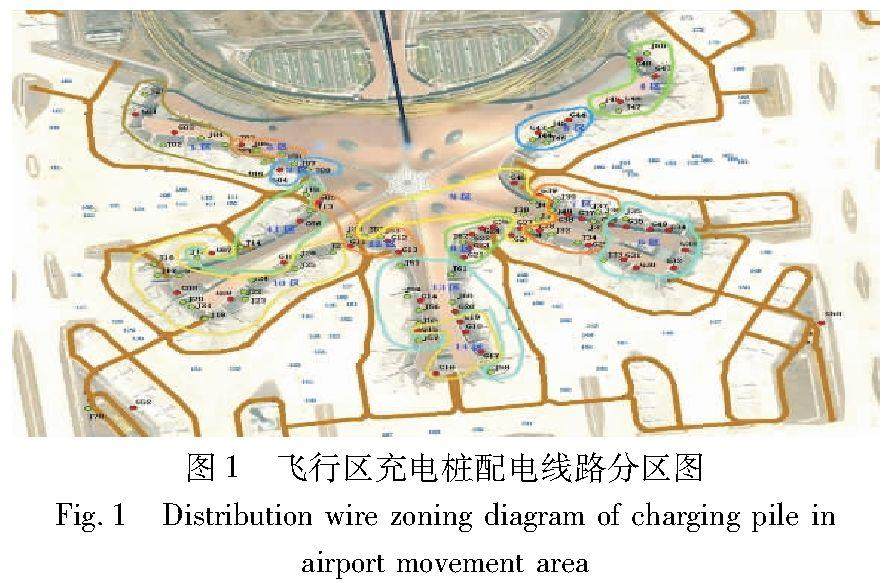
算法研究探讨 | 两阶段机场多特种车辆协同充电调度策略
算法研究探讨 | 两阶段机场多特种车辆协同充电调度策略
-
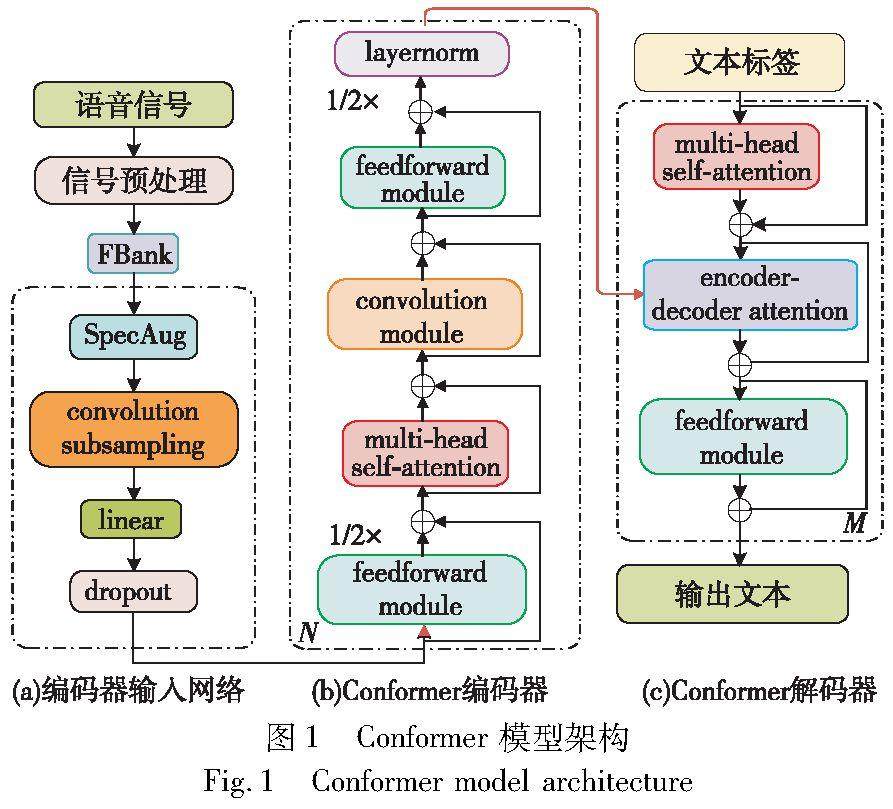
算法研究探讨 | 基于Conformer的端到端语音识别方法
算法研究探讨 | 基于Conformer的端到端语音识别方法
-
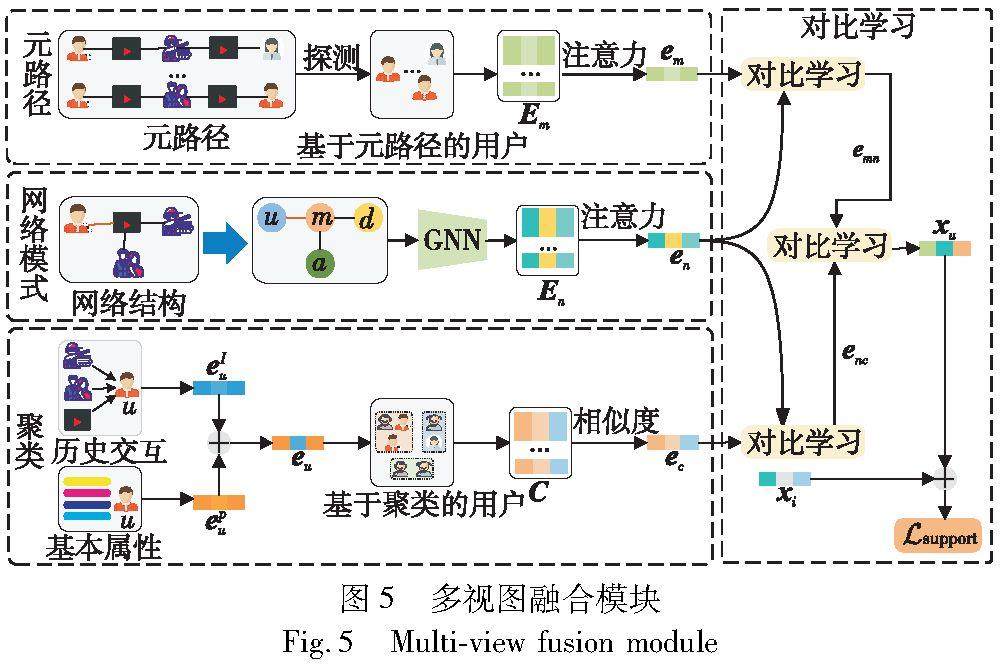
算法研究探讨 | 基于元学习的多视图对比融合冷启动推荐算法
算法研究探讨 | 基于元学习的多视图对比融合冷启动推荐算法
-

算法研究探讨 | 基于反向延长增强的对抗生成网络推荐算法
算法研究探讨 | 基于反向延长增强的对抗生成网络推荐算法
-
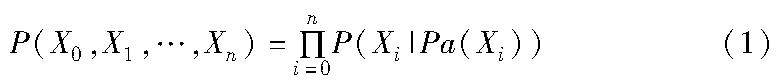
算法研究探讨 | 基于概念漂移检测的数字孪生流程预测模型
算法研究探讨 | 基于概念漂移检测的数字孪生流程预测模型
-
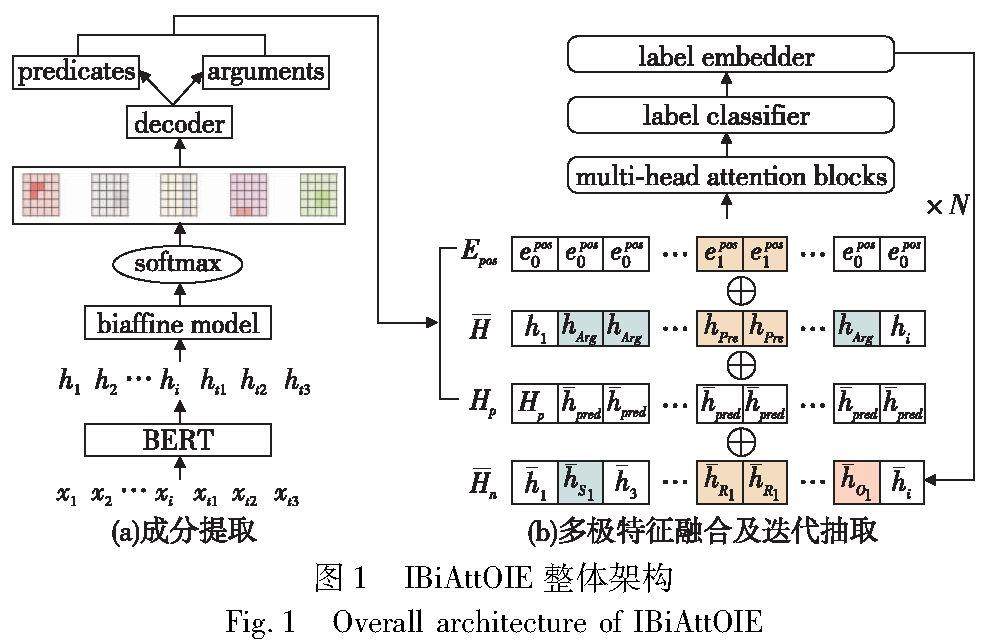
算法研究探讨 | 基于双仿射注意力的迭代式开放域信息抽取
算法研究探讨 | 基于双仿射注意力的迭代式开放域信息抽取
-
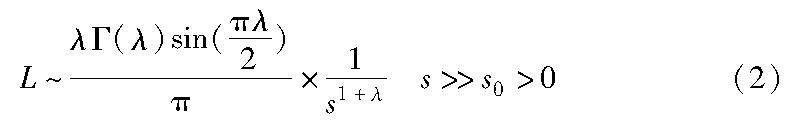
算法研究探讨 | 基于动态双种群的黏菌和花粉混合算法
算法研究探讨 | 基于动态双种群的黏菌和花粉混合算法
-

算法研究探讨 | 增强型野马优化算法及其工程应用
算法研究探讨 | 增强型野马优化算法及其工程应用
-

算法研究探讨 | 面向在线率差异的SaaS订阅限额及资源配置组合优化
算法研究探讨 | 面向在线率差异的SaaS订阅限额及资源配置组合优化
-

算法研究探讨 | 增强学习标签相关性的多标签特征选择方法
算法研究探讨 | 增强学习标签相关性的多标签特征选择方法
-
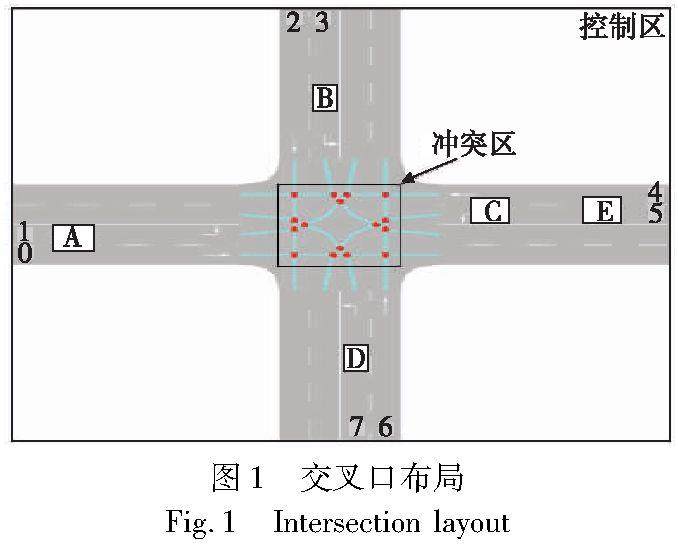
算法研究探讨 | 车路协同下的无信号交叉口车辆通行调度策略
算法研究探讨 | 车路协同下的无信号交叉口车辆通行调度策略
-
算法研究探讨 | 基于Z-Score动态压缩的高效联邦学习算法
算法研究探讨 | 基于Z-Score动态压缩的高效联邦学习算法
-
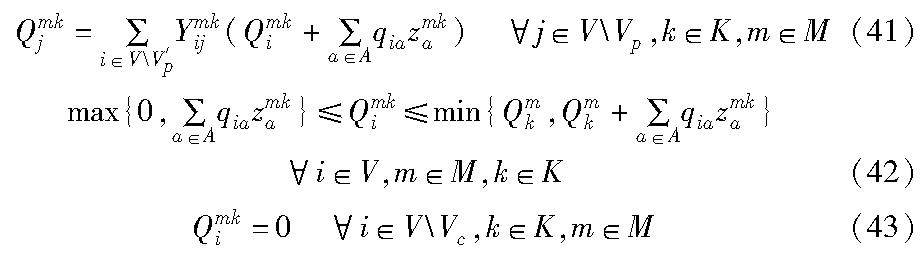
算法研究探讨 | 时变路网下考虑碳排放的需求响应型公交调度优化模型
算法研究探讨 | 时变路网下考虑碳排放的需求响应型公交调度优化模型
-
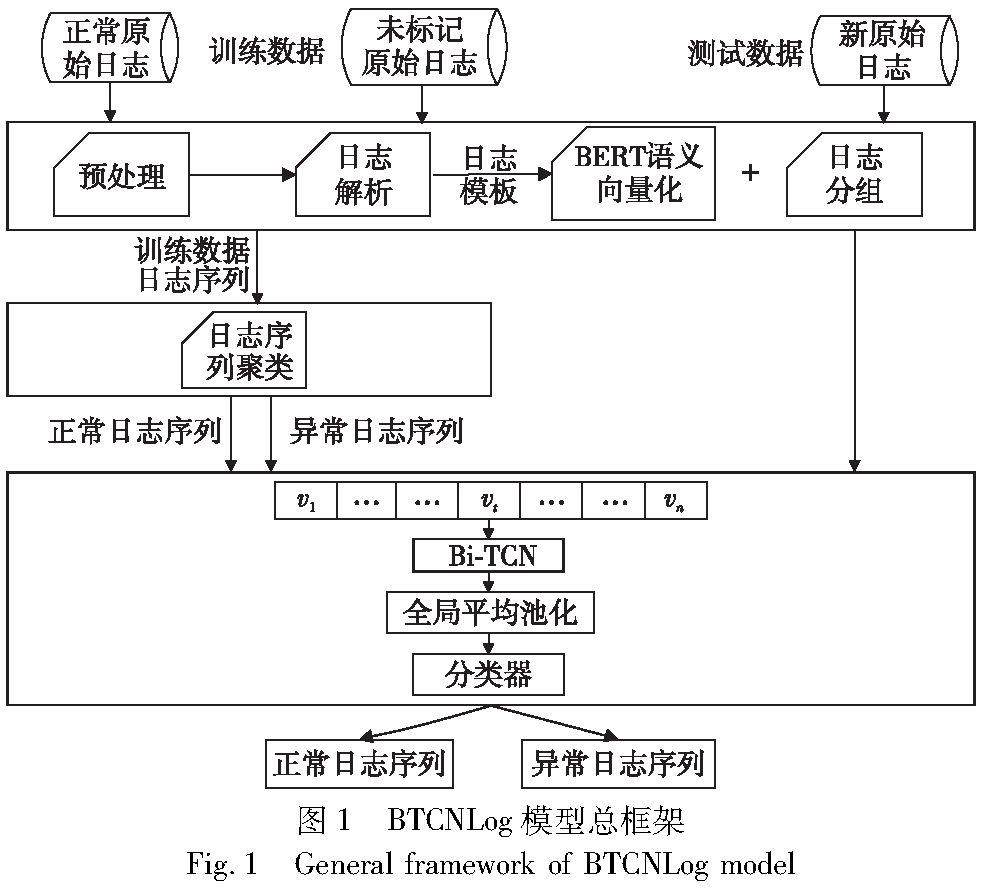
系统应用开发 | 基于双向时间卷积网络的半监督日志异常检测
系统应用开发 | 基于双向时间卷积网络的半监督日志异常检测
-

系统应用开发 | 灾害场景下基于MADRL的信息收集无人机部署与节点能效优化
系统应用开发 | 灾害场景下基于MADRL的信息收集无人机部署与节点能效优化
-
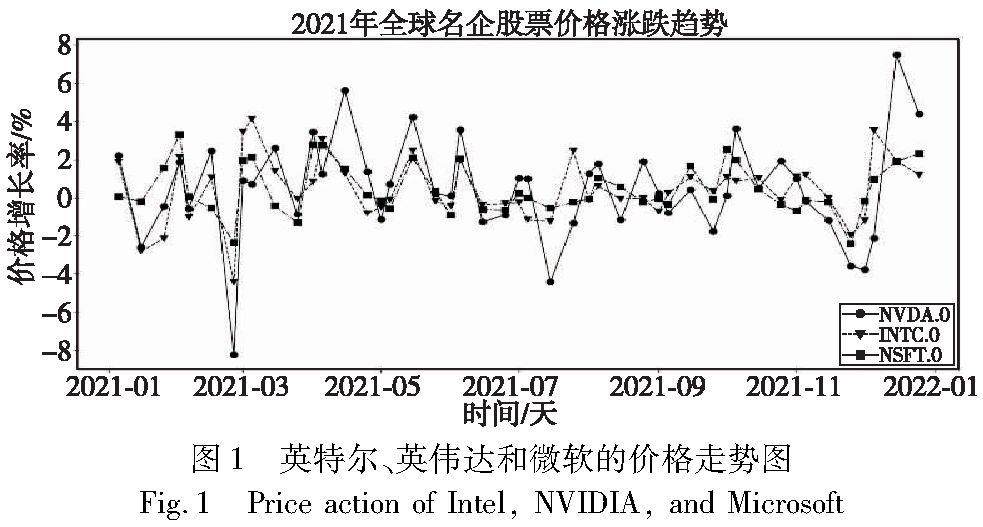
系统应用开发 | 基于动态异构网络的股价预测
系统应用开发 | 基于动态异构网络的股价预测
-
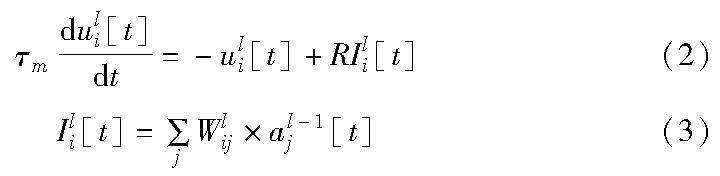
系统应用开发 | 跨脉冲传播的深度脉冲神经网络训练方法
系统应用开发 | 跨脉冲传播的深度脉冲神经网络训练方法
-
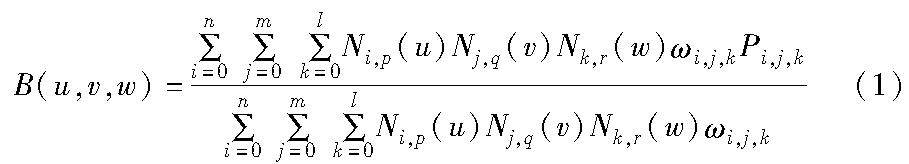
系统应用开发 | NURBS体参数化模型的无支撑打印算法
系统应用开发 | NURBS体参数化模型的无支撑打印算法
-

软件技术研究 | 基于对比学习的跨语言代码克隆检测方法
软件技术研究 | 基于对比学习的跨语言代码克隆检测方法
-
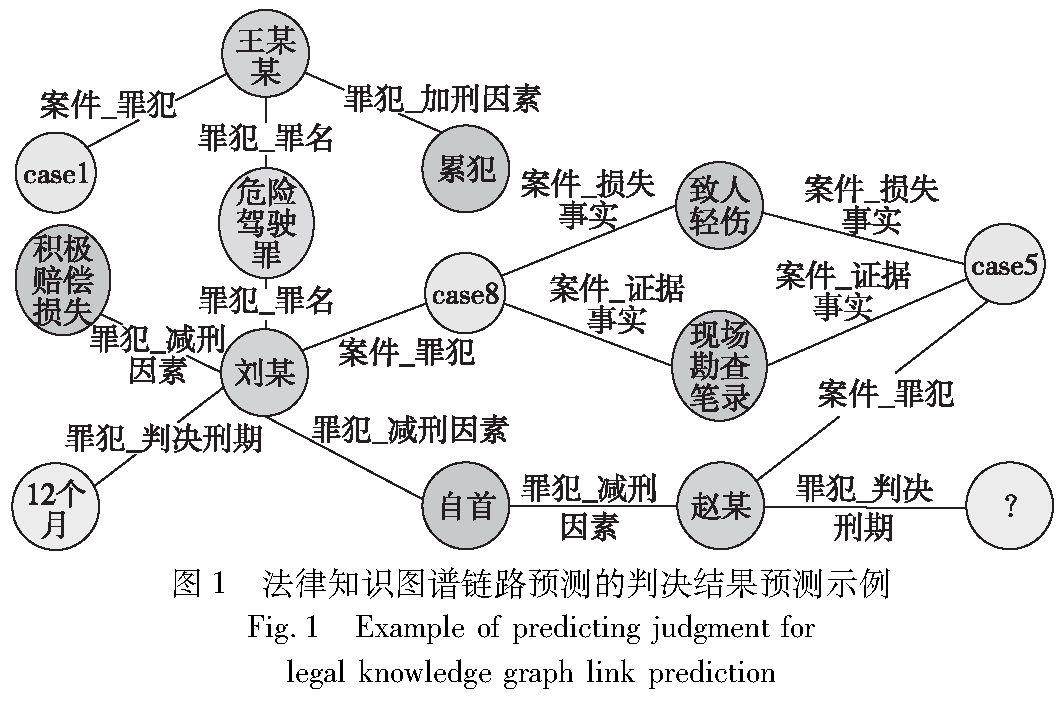
软件技术研究 | 基于知识图谱的案件特征增强法律判决预测
软件技术研究 | 基于知识图谱的案件特征增强法律判决预测
-
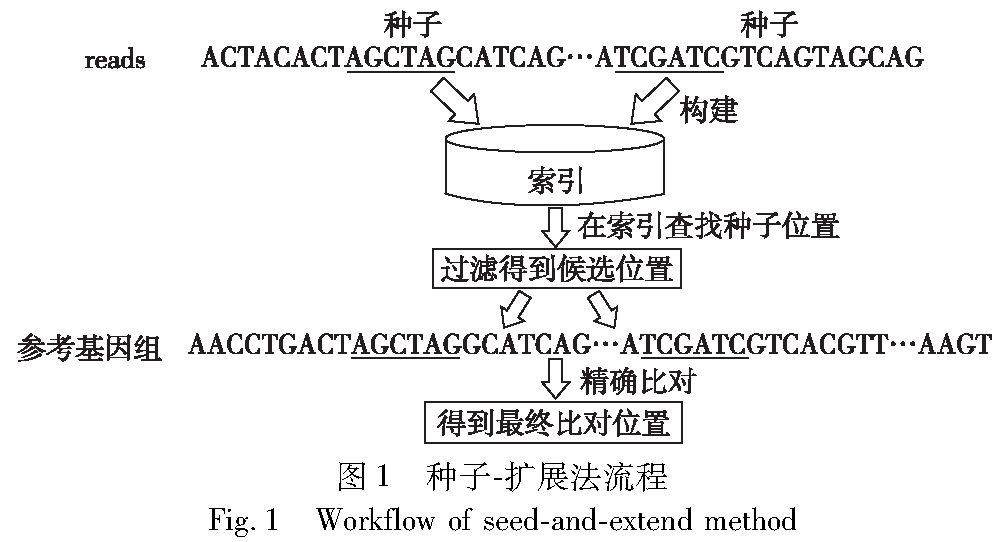
软件技术研究 | 串联重复序列比对的位置筛选方法
软件技术研究 | 串联重复序列比对的位置筛选方法
-

网络与通信技术 | MSs-MEC中基于DRL的服务缓存和任务迁移联合优化算法
网络与通信技术 | MSs-MEC中基于DRL的服务缓存和任务迁移联合优化算法
-
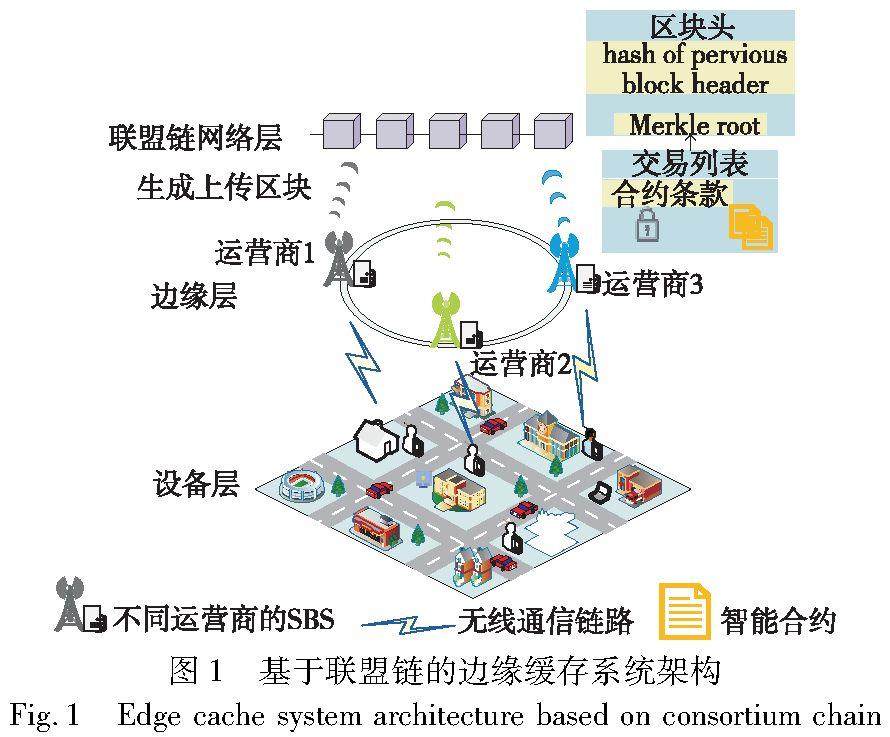
网络与通信技术 | 基于联盟链的边缘缓存系统中最佳缓存策略设计
网络与通信技术 | 基于联盟链的边缘缓存系统中最佳缓存策略设计
-

信息安全技术 | 软件漏洞模糊测试的关键分支探索及热点更新算法
信息安全技术 | 软件漏洞模糊测试的关键分支探索及热点更新算法
-
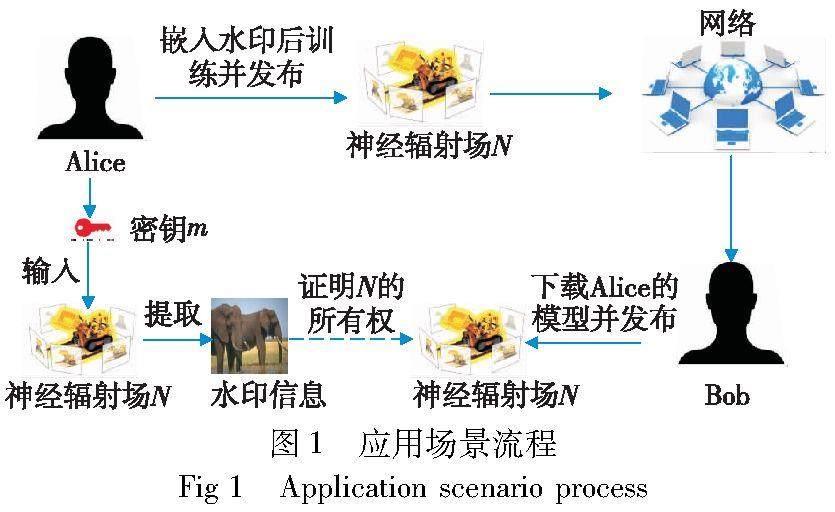
信息安全技术 | 面向神经辐射场的水印算法
信息安全技术 | 面向神经辐射场的水印算法
-
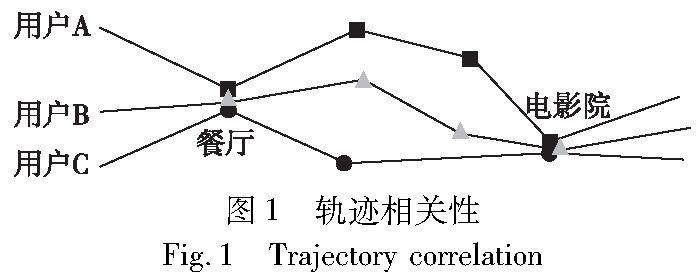
信息安全技术 | 基于用户相关性的差分隐私轨迹隐私保护方案
信息安全技术 | 基于用户相关性的差分隐私轨迹隐私保护方案
-
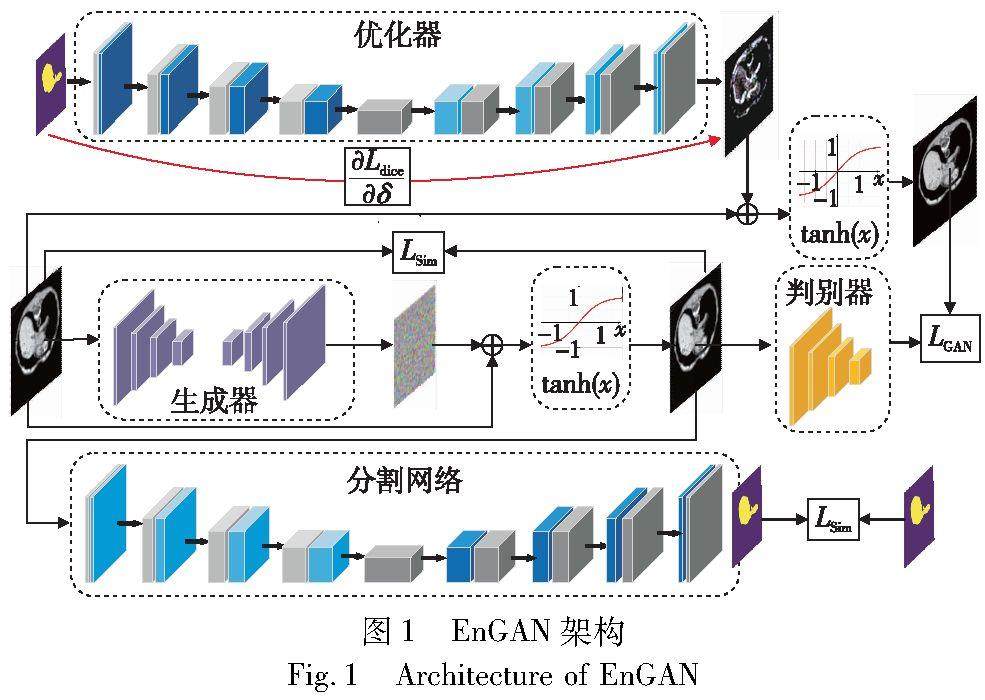
图形图像技术 | EnGAN:医学图像分割中的增强生成对抗网络
图形图像技术 | EnGAN:医学图像分割中的增强生成对抗网络
-

图形图像技术 | 基于语义一致性约束与局部-全局感知的多模态3D视觉定位
图形图像技术 | 基于语义一致性约束与局部-全局感知的多模态3D视觉定位
-
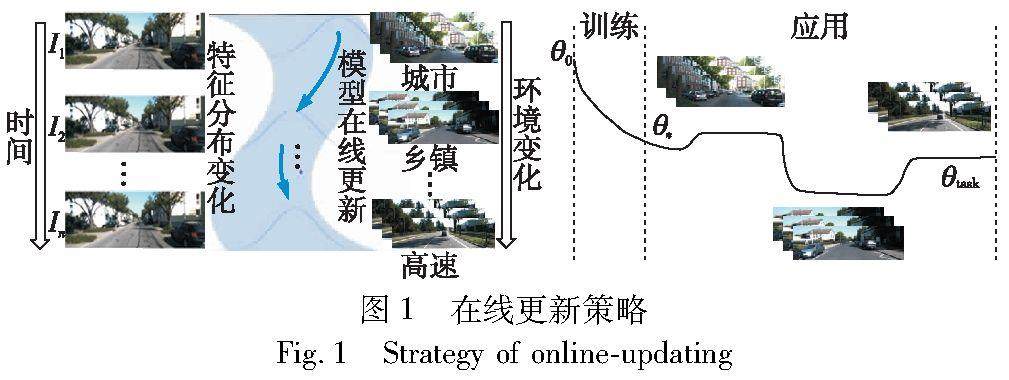
图形图像技术 | 一种在线更新的单目视觉里程计
图形图像技术 | 一种在线更新的单目视觉里程计
-
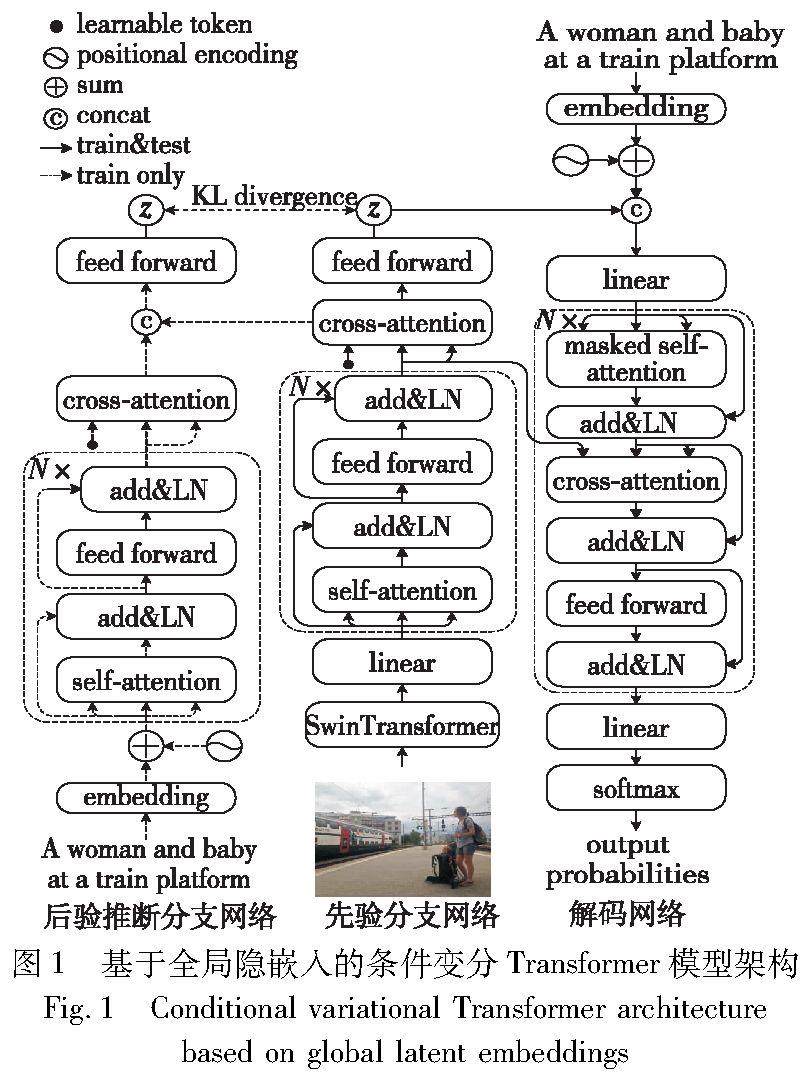
图形图像技术 | 基于全局与序列变分自编码的图像描述生成
图形图像技术 | 基于全局与序列变分自编码的图像描述生成
-
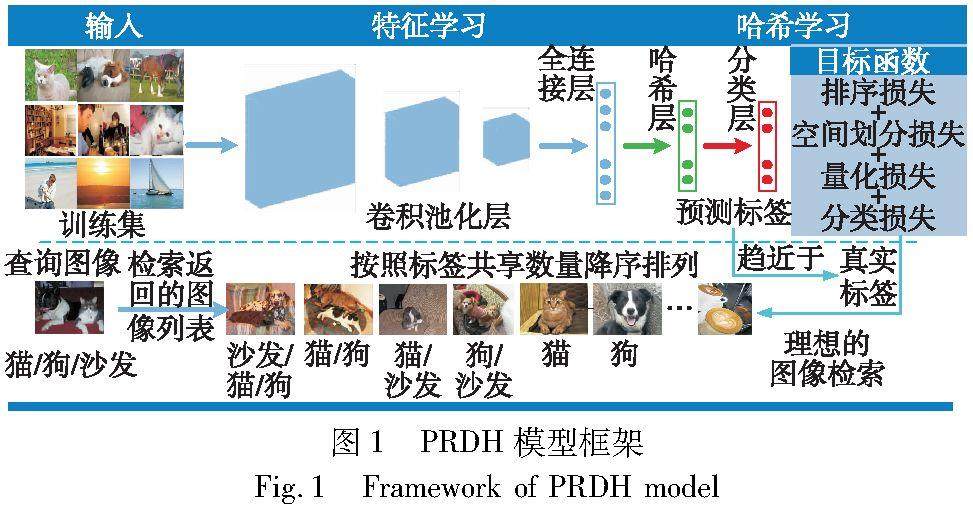
图形图像技术 | 具有性能感知排序的深度监督哈希用于多标签图像检索
图形图像技术 | 具有性能感知排序的深度监督哈希用于多标签图像检索
-
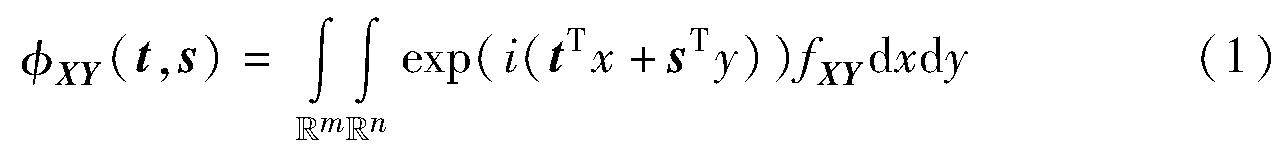
图形图像技术 | 深度掩膜布朗距离协方差小样本分类方法
图形图像技术 | 深度掩膜布朗距离协方差小样本分类方法
-
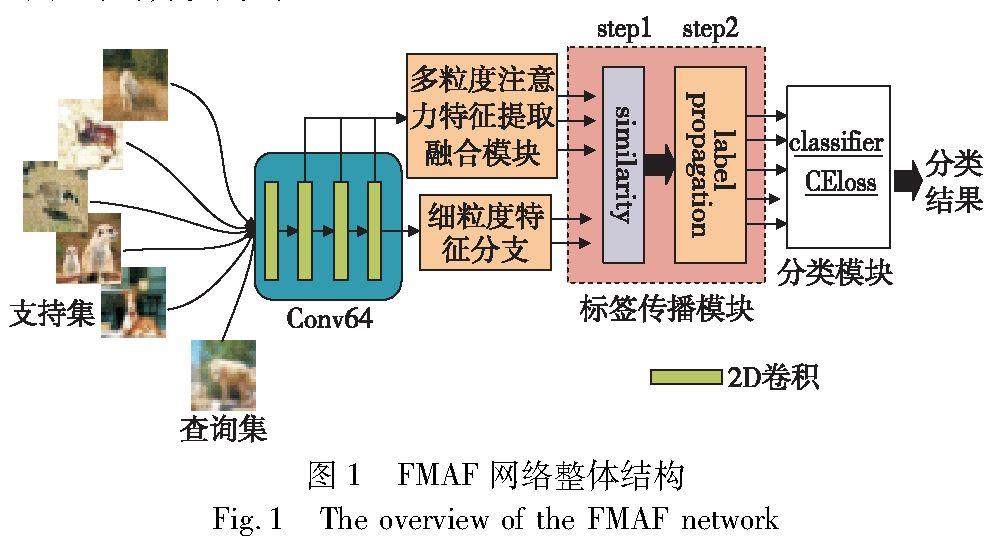
图形图像技术 | 融合多粒度注意力特征的小样本分类模型
图形图像技术 | 融合多粒度注意力特征的小样本分类模型



















 登录
登录